
Index:
Creating and Mounting SDFS File Systems
Mounting SDFS Volumes as NFS Shares
Managing SDFS Volumes for Virtual Machines
Managing SDFS Volumes through Extended Attributes
File-system Snapshots for SDFS Volumes
Dedup Storage Engine
Cloud Based Deduplication
Dedup Storage Engine Memory
Data Chunks
File and Folder Placement
Other options and Extended Attributes
Introduction:
This is intended to be a detailed guide for the SDFS file-system. For most purposes, the Quickstart Guide will get you going but if you are interested in advanced topics, this is the place to look.
SDFS is a distributed and expandable filesystem designed to provide inline deduplication and flexiblity for applications. Services such as backup, archiving, NAS storage, and Virtual Machine primary and secondary storage can benefit greatly from SDFS.
SDFS can be deployed as a standalone filesystem and provide inline deduplication. The deduplication can store data on a number of back ends including:
- Object Storage
- AWS S3
- Glacier
- S3 compliant back ends
- Google Cloud Storage
- Azure Blob Storage
- Swift
- Local Filesystem
- EXT4
- NTFS (Windows)
- XFS
Features:
SDFS for read and write activity in addition to the features below.
- High Availability : All block data is fully recoverable from object storage, including :
- MetaData
- Hashtable
- Unique Data
- Global Deduplication from any application that writes to an opendedupe volume
- Expand backend storage without having to offline the volume
- Unlimited Snapshot capability without IO impact
- Efficient, deduplication aware replication
Architecture:
- SDFS file-system service (Volume)
- Deduplication Storage Engine (DSE)
- Data Chunks

END TO END PROCESS
SDFS FILE META-DATA
Each logical SDFS file is represented by two different actual pieces of metadata and held in two different files. The first piece of metadata is called the “MetaDataDedupFile” this file is stored in a filesystem structure that directly mimics the filesystem namespace that is presented when the filesystem is mounted. As an example, each of these files is named the same as it appears when it is mounted and looks as if its in the same directory structure under “/opt/sdfs/volumes/<volume-name>/files/”. This file contain all of the filesystem attributes associated with the file, including size, atime, ctime, acls, and link to the associated map file.
The second meta-data file is the mapping file. This file contains the list of records, corresponding to locations to where the blocks represent data in the file. Each record contains a hash entry, whether the data was a duplicate, and when the data is stored on remote nodes, what nodes that data can be found on.
This data is located in “/opt/sdfs/volumes/<volume-name>/ddb/”
each record has the following data structure
| dup (1 byte) | hash (hash algo length) | reserverd 1(byte) | hash location 8 bytes |
The locations field is an 8 byte array that represents a long integer. The long integer represents the Archive File where the data associated with the specific chunk in question can be found.
SDFS Stores all data in archive files that combine multiple data chunks of deduplicated data into larger files. This allows for more efficient storage management and less uploads to the cloud.
WRITE BUFFERS
SDFS Write buffers store data before it is deduplicated. The size of the buffers should be set appropriate to the IO pattern and type of data that is written.
The write buffer size is detemined at mkfs.sdfs initialization with the parmeter –io-chunk-size. By default its set to 256KB. When the parameter –backup-volume is selected the chunk size is set to 40MB.
A larger buffer size will allow for better deduplication rates and faster streamed IO. A smaller chunk size will allow for faster random IO.
This parameter cannot be changed after the volume is mounted.
WRITING DATA
When data is written to SDFS it is sent to the File-System Process for the kernel via the fuse library or dokan library. SDFS grabs the data from the fuse layer api and breaks the data into fixed chunks. These chunks are associated to fixed positions within the file as they were written. These chunks are immediately cached on a per file basis for active IO read and writes in a fifo buffer. The size of this fifo buffer is set to 1MB-80MB by default but can be changed via the “max-file-write-buffers” attribute within the SDFS configuration file.
When data expires from the fifo buffer it is moved to a flushing buffer. This flushing buffer is emptied by a pool of threads configured by “write-threads” attribute. These threads perform the process of computing the hash for the block of data, searching the system to see if the hash/data has already been stored, on what nodes the data is stored(not applicable for standalone), confirming the data has been persisted, and finally writing the record associated with the block to the mapping file.
READING DATA
When data is read from SDFS the requested file position and requested data length is sent through the fuse layer to the SDFS application. The record(s) associated with the file position and length are then looked up in the mapping file and the block data is recalled by either looking up the long integer associated with the archive file where the data is located, or by the hash if that first case fails.
READING DATA FROM AMAZON GLACIER
SDFS can utilize Storage Lifestyle policies with Amazon to support moving data to glacier. When data is read from Amazon Glacier, the DSE first tries the retrieve the data normally, as if its any S3 blob, if this process fails because the blob has been moved to glacies, the DSE then informs the OpenDedupe volume service that the data has been archived. The OpenDedupe Volume Service initiates an glacier archival retrieval process for all blocks associated to chunks unused by file being read. The read operation will be blocked until all blocks have been successfully restored from glacier.
SDFS FILE-SYSTEM SERVICE
The SDFS File-System (FSS) service is synonymous with the operating system concept of a Volume and filesystem as it performs the function of both. It is logical container that is responsible for all file system level activity. This includes filesystem IO activity, chunking data into fixed blocks for deduplication, file system statistics, as well as all enhanced functions such as snapshots. Each File System Service or volume contains a single SDFS namespace, or filesystem instance and is responsible for presenting and storing individual files and folders. The volume is mounted through “mount.sdfs”. This is the primary way users, applications, and services interact with SDFS.
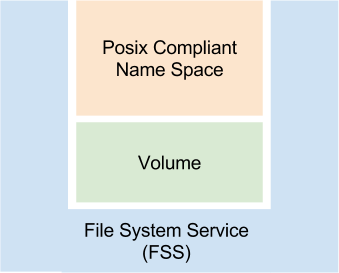
The SDFS file-system service provides a typical POSIX compliant view of deduplicated files and folders to volumes. The SDFS filesystem services store meta-data regarding files and folders. This meta data includes information such as file size, file path, and most other aspects of files and folders other than the actual file data. In addition to meta data the SDFS file-system service also manages file maps that identify data location to dedup/undeduped chunk mappings. The chunks themselves live either within within the local Deduplication Storage Engine or in the cluster depending on the configuration.
SDFS Volumes can be exported through ISCSI or NFS.
File-System services (FSS) will add the available storage on the DSE to its capacity and begin to actively writing unique blocks of data to that node and reference that node id for retrieval. DSE nodes are written to based on a weighted random distribution
If the responses have met the cluster redundancy requirements then the FSS will store the cluster node numbers and the hash in the map file associated with the specific write request. It the block has not yet been stored or if the block does not meet the cluster redundancy requirements then the block will be written to nodes that have not already stored that block. The determination where that block will be stored is based on distribution algorithm described above. These write are done in unicast to the specific storage nodes.
Deduplication Storage Engine
The Deduplication Storage Engine (DSE) stores, retrieves, and removes all deduped chunks. The deduplication storage engine can is run as part of an SDFS Volume. Chunks of data are stored on disk, or at a cloud provider, and indexed for retrieval with a custom written hash table. The DSE database is stored in /opt/sdfs/volumes/<volume-name>/chunkstore/hdb-<unique id>/ .
Data Blocks
Unique data chunks are stored together in Archive Files by the Dedupe Storage Engine(DSE) either on disk or in the cloud. The dedupe storage engine stores collections of data chunks, in sequence, within data blocks in the the chuckstore directory. By default the data block size is no more than 40MB but can be set to anything up to 256MB. New blocks are closed and are no longer writable when either their size is reached or the block times out waiting for new data. The timeout is 6 seconds by default. Writable blocks are stored in chunkstore/chunks/outgoing/.
The DSE creates new blocks as data is unque data is written into the DSE. Each new block is designated by a unique long integer. When unique data is written in, the DSE either compresses/encrypts the chunk and then writes the chunk into a new block in sequence. It then stores a reference to the unique chunk hash and the block’s unique id. The block, itself keeps track of where unique chunks are located in a map file associated with each chunk. As blocks reach their size limit or timeout they are then closed for writing and then either uploaded to the cloud and cached locally or moved to a permanent location on disk /chunkstore/chunks/[1st three numbers of unique id]/. The map file and the blocks are stored together.
Cloud Storage of Data Blocks
When data is uploaded to the cloud, the DSE creates a new thread to upload the closed block. The number of blocks that can be simultaneously uploaded is 16 by default but can be changed within the xml config (io-threads). For slower connections it may make sense to lower this number or raise it for faster connections up to 64 threads. Data Blocks are stored in the bucked under /blocks/ sub directory and the associated maps are stored in the /keys/ directory.

Data chunks are always read locally when requested by the volume. If cloud storage is leveraged, the data block where a requested chunk is located is retrieved from the cloud storage provider and cached locally. The unique chunk is then read from the local cache and restored.
If data is stored in an Amazon Glacier repository, the DSE informs the volume that the data is archived. The volume will then initiate an archive retrieval process.
Data Chunk
Data Chunks are the unit by which raw data is processes and stored with SDFS. Chunks of data are stored either with the Deduplication Storage Engine or the SDFS file-system service depending on the deduplication process. Chunks are, by default hashed using the SIP Hash 128. SDFS also includes other hashing algorithms but SIP is fast, collision resistant, and requires half the footprint of sha256.
Here are a few other facts regarding unique data redundancy if data is written to the cloud:
- Unique data is written to mutiple DSE nodes asynchronously.
- If two volumes specifiy different redundancy requirements and share unique data, redundancy will be met based on the volume with the highest redundancy requirement.
- If the number of DSEs drops below the replica requirement writes will still occur to the remaining DSE nodes.
Planning SDFS Your Architecture:
Standalone VS. Cloud Storage
We deciding on a standalone architecture versus cloud storage consider the following advantages of each :
STANDALONE ADVANTAGES :
- IO Speeds : Reads and writes will all be significantly faster using local storage vs cloud storage.
CLOUD ADVANTAGES :
- High Availability : The entire volume is replicated to the cloud. This means that if you loose your local volume, you can recover all of the data from the cloud.
- Scalability : SDFS scales better with cloud storage because only a small subset of the unique data is stored locally.
- Global Deduplication : Multiple SDFS volumes can share the same cloud storage bucket and share each other’s data.
To create a volume you will want to consider the following:
Fixed and Variable Block Deduplication
SDFS Can perform both fixed and variable block deduplication. Fixed block deduplication takes fixed blocks of data and hashes those blocks. Variable block deduplication attempts to find natural breaks within stream of data an creates variable blocks at those break points.
Fixed block deduplication is performed at volume defined fixed byte buffers within SDFS. These fixed blocks are defined when the volume is created and is set at 4k by default but can be set to a maximum value of 128k. Fixed block deduplication is very useful for active structured data such as running VMDKs or Databases. Fixed block deduplication is simple to perform and can therefore be very fast for most applications.
Variable block deduplication is performed using Rabin Window Borders (http://en.wikipedia.org/wiki/Rabin_fingerprint). SDFS uses fixed buffers of 256K and then runs a rolling hash across that buffer to find natural breaks. The minimum size of a variable block is 4k and the maximum size is 32k. Variable block deduplication is very good at finding duplicated blocks in unstructured data such as uncompressed tar files and documents. Variable Block deduplication typically will create blocks of 10k-16k. This makes Variable block deduplication more salable than fixed block deduplication when it is performed at 4k block sizes. The downside of Variable block deduplication is that it can be computationally intensive and sometimes slower for write processing.
Creating and Mounting SDFS File Systems:
Both stand alone and clustered SDFS volumes are created through the sdfscli command line. There are many options available within the command line but most of the options are set to their optimal setting. Multiple SDFS Volumes can be hosted on a single host. All volume configurations are stored, by default in /etc/sdfs .
CREATING A STANDALONE SDFS VOLUME
A simple standalone volume named “dedup” with a dedup capacity of 1TB and using variable block deduplication run the following command:
mkfs.sdfs --volume-name=dedup --volume-capacity=1TB
The following will create a volume that has a dedup capacity of 1TB and a unique block size of 32K
mkfs.sdfs --volume-name=dedup --volume-capacity=1TB --io-chunk-size=32
By default volumes store all data in the folder structure /opt/sdfs/<volume-name>. This may not be optimal and can be changed before a volume is mounted for the first time. In addition, volume configurations are held in the /etc/sdfs folder. Each volume configuration is created when the mkfs.sdfs command is run and stored as an XML file and its naming convention is <volume-name>-volume-cfg.xml.
SDFS Volumes are mounted with the mount.sdfs command. Mounting a volume typically typically is executed by running “mount.sdfs -v <volume-name> -m <mount-point>. As an example “mount.sdfs -v sdfs -m /media/dedup will mount the volume as configured by /etc/sdfs/sdfs-volume-cfg.xml to the path /media/dedup. Volume mounting options are as follows:
Volumes are unmounted automatically when the mount.sdfs is killed or the volume is unmounted using the umount command.
To mount a volume run
Exporting SDFS Volumes:
SDFS can be shared through NFS or ISCSI exports on Linux kernel 2.6.31 and above.
NFS Exports
SDFS is supported and has been tested with NFSv3. NFS opens and closes files with every read or write. File open and closes are expensive for SDFS and as such can degrade performance when running over NFS. SDFS volumes can be optimized for NFS with the option “–io-safe-close=false” when creating the volume. This will leave files open for NFS reads and writes. Files data will still be sync’d with every write command, so data integrity will still be maintained. Files will be closed after an inactivity period has been reached. By default this inactivity period is 15 (900) seconds minutes but can be changed at any time, along with the io-safe-close option within the xml configuration file located in /etc/sdfs/<volume-name>-volume-cfg.xml.
To export an SDFS Volume of FSS via NFS use the fsid=<a unique id> option as part of the syntax in your /etc/exports. As an example, an SDFS volume is mounted at /media/pool0 and you wanted to export it to the world you would use the following syntax in your /etc/exports
/media/pool0 *(rw,async,no_subtree_check,fsid=12)
ISCSI Exports
SDFS is supported and has been tested with LIO using fileio. This means that LIO serves up a file on an SDFS volume as a virtual volume itself. On the SDFS volume the exported volumes are represented as large files within the filesystem. This is a common setup for ISCI exports. The following command squence will server up an 100GB ISCSI volume from a SDFS filesystem mounted at /media/pool0 without any authentication.
Managing SDFS Volumes for Virtual Machines:
It was the original goal of SDFS to be a file system of virtual machines. Again, to get proper deduplication rates for VMDK files set io-chunk-size to “4” when creating the volume. This will match the chunk size of the guest os file system usually. NTFS allow 32k chunk sizes but not on root volumes. It may be advantageous, for Windows guest environments, to have the root volume on one mounted SDFS path at 4k chunk size and data volumes in another SDFS path at 32k chunk sizes. Then format the data ntfs volumes, within the guest, for 32k chunk sizes. This will provide optimal performance.
Managing SDFS Volumes through SDFS command line
Online SDFS management is done through sdfscli. This is a command line executable that allows access to management and information about a particular SDFS volume. The volume in question must be mounted when the command line is executed. below are the command line parameters that can be run. Also help is available for the command line when run as sdfscli –help . The volume itself will listen on as an https service on a port starting with 6442. By default the volume will only listen on the loopback adapter. This can be changed during volume creation but adding the “enable-replication-master” option. In addition, after creation, this can be changed by modifying the “listen-address” attribute in the sdfscli tag within the xml config. If multiple volumes are mounted the volume will automatically choose the next highest available port. The tcp port can be determined by running a “df -h” the port will be designated after the “:” within the device name.
usage: sdfs.cmd <options>
File-system Snapshots:
SDFS provides snapshot functions for files and folders. The snapshot command is “sdfscli –snapshot –snapshot-path=<relative-target-path> –file-path=<relative-source-path>”. The destination path is relative to the mount point of the sdfs filesystem.
As an example to snap a file “/mounted-sdfs-volume/source.bin” to /mounted-sdfs-volume/folder/target.bin you would run the following command:
sdfscli –snapshot –snapshot-path=folder/target.bin –file-path=source.bin
The snapshot command makes a copy of the MetaDataDedupFile and the map file and associates this copy with the snapshot path. This means that no actual data is copied and unlimited snapshots can be created, without performance impact to the target or source, since they not associated or linked in any way.
SDFS File System Service Volume Storage Reporting, Utilization, and Compacting A Volume
Reporting
An FSS reports is size and usage to the operating system, by default, based on the capacity and current usage of the data stored within the DSE. This means that a volume could have a much larger amount of logical data than, if all the file sizes in the filesystem was added up, than is reported to the OS. This method of reporting is the most accurate as it reports actual physical capacity and with deduplication you should see the current size as much smaller that the logical data would report.
It is also possible for FSS report the logical capacity and utilization of the volume. This means that SDFS will report the logical capacity, as specified during volume creation as “–volume-capacity” and current usage based on the logical size or the files as reported during an “ls” command. To change the reporting the following parameters will need to be changed in the sdfs xml configuration when the volume is not mounted.
To set the FSS to report capacity based on the –volume-capacity
use-dse-capacity=”false”
To set the FSS to report current utilization based on logical capacity
use-dse-size=”false”
Volume Size can reported many ways. Both operating system tools and the sdfscli can be used to view capacity and usage of a FSS. A quick way to view the way the filesystem sees a SDFS Volume is running “df -h”. The os will report the volume name as a concatenation of the config and the port the the sdfscli service is listening on. The port is important because it can be used connect to multiple volumes from the sdfscli using the “–port” option. The size and used columns either report the capacity and usage for the DSE or the logical capacity and usage of the volume, depending on configuration.

Volume usage statistics are also reported by the sdfs command line. For both standalone and volumes in a cluster configuration the command line “sdfscli.sh –volume-info” can be executed. This will output statistics about the local volume.

Utilization
SDFS Volumes grow over time as more unique data is stored. As unique data is de-referenced from volumes it is deleted from the DSE, if not claimed, during the garbage collection process. Deleted blocks are overwritten over time. Typically this allows for efficient use of storage but if data is aggressively added or deleted a volume can have a lot of empty space and fragmentation where unique blocks that have been deleted used to reside. This option is only available for standalone volumes.
Dedup Storage Engine (DSE):
The Dedup Storage Engine (DSE) provides services to store, retrieve, and remove deduplicated chunks of data. Each SDFS Volume contains its and manages its own DSE.
Dedup Storage Engine – Cloud Based Deduplication:
The DSE can be configured to store data to the Amazon S3 cloud storage service or Azure. When enabled, all unique blocks will be stored to a bucket of your choosing. Each block is stored and an individual blob in the bucked. Data can be encrypted before transit, and at rest with the S3 cloud using AES-256 bit encryption. In addition, all data is compressed by default before sent to the cloud.
The purpose of deduplicating data before sending it to cloud storage to minimize storage and maximize write performance. The concept behind deduplication is to only store unique blocks of data. If only unique data is sent to cloud storage, bandwidth can be optimized and cloud storage can be reduced. Opendedup approaches cloud storage differently than a traditional cloud based file system. The volume data such as the name space and file meta-data are stored locally on the the system where the SDFS volume is mounted. Only the unique chunks of data are stored at the cloud storage provider. This ensures maximum performance by allowing all file system functions to be performed locally except for data reads and writes. In addition, local read and write caching should make writing smaller files transparent to the user or service writing to the volume.

Cloud based storage has been enabled for S3 Amazon Web service and Azure. To create a volume using cloud storage take a look at the cloud storage guide here.
Dedup Storage Engine Memory:
The SDFS Filesystem itself uses about 3GB of RAM for internal processing and caching. For hash table caching and chunk storaged kernel memory is used. It is advisable to have enough memory to store the entire hashtable so that SDFS does not have to scan swap space or the file system to lookup hashes.
To calculate memory requirements keep in mind that each stored chunk takes up approximately 256 MB of RAM per 1 TB of unique storage.
Dedup Storage Engine Crash Recovery:
If a Dedup Storage Engine crashes, a recovery process will be initiated on the next start. In a clusterned node setup, a DSE determines if it was not shut down gracefully if <relative-path>/chunkstore/hdb/.lock exists on startup. In a standalone setup the SDFS volume determines crash if the closed-gracefully=”false” within the configuration xml. If a crash is determined, the Dedup Storage Engine will go through the recovery process.
The DSE recovery process re-hashes all of the blocks stored on disk, or get the hashes from the cloud. It then verifies the hashes are in the hash database and adds an entry if none exists. This process will claim all hashes, even those previously dereferenced hashes that were removed during garbage collection.
In a standalone setup, the volume will then perform a garbage collection to de-reference any orphaned block. In a clustered configuration the garbage collection will need to be performed manually.
Data Chunks:
The chunk size must match for both the SDFS Volume and the Deduplication Storage Engine. The default for SDFS is to store chunks at 4K size. The chunk size must be set at volume and Deduplication Storage Engine creation. When Volumes are created with their own local Deduplication Storage Engine chunk sizes are matched up automatically, but, when the Deduplication Storage Engine is run as a network service this must be set before the data is stored within the engine.
Within a SDFS volume chunksize is set upon creation with the option –io-chunk-size. The option –io-chunk-size sets the size of chunks that are hashed and can only be changed before the file system is mounted to for the first time. The default setting is 4K but can be set as high as 128K. The size of chucks determine the efficient at which files will be deduplicated at the cost of RAM. As an example a 4K chunk size SDFS provides perfect deduplication for Virtual Machines (VMDKs) because it matches the cluster size of most guest os file systems but can cost as much as 6GB of RAM per 1TB to store. In contrast setting the chunk size to 128K is perfect of archived, unstructured data, such as rsync backups, and will allow you to store as much as 32TB of data with the same 6GB of memory.
To create a volume that will store VMs (VMDK files) create a volume using 32K chunk size as follows:
sudo ./mkfs.sdfs –volume-name=sdfs_vol1 –volume-capacity=150GB –io-chunk-size=32
As stated, when running SDFS Volumes with a local DSE chunksizes are matched automatically, but if running the DSE as a network service, than a parameter with the DSE configuration XML file will need to be set before any data is stored. The parameter is:
page-size=”<chunk-size in bytes>”.
As an example to set a 4k chunk size the option would need to be set to:
page-size=”4096″
File and Folder Placement:
Deduplication is IO Intensive. SDFS, by default writes data to /opt/sdfs. SDFS does a lot of writes went persisting data and a lot of random IO when reading data. For high IO intensive applications it is suggested that you split at least the chunk-store-data-location and chunk-store-hashdb-location onto fast and separate physical disks. From experience these are the most IO intensive stores and could take advantage of faster IO.
Other options and extended attributes:
SDFS uses extended attributes to manipulate the SDFS file system and files contained within. It is also used to report on IO performance. To get a list of commands and readable IO statistics run “getfattr -d *” within the mount point of the sdfs file system.
sdfscli –file-info –file-path=<relative-path to file or folder>
SDFS Volume Replication:
SDFS now provides asynchronous master/slave volume and subvolume replication through the sdfsreplicate service and script. SDFS volume replication takes a snapshot of the disignated master volume or subfolder and then replicated meta-data and unique blocks to the secondary, or slave, SDFS volume. Only unique blocks that are not already stored on the slave volume are replicated so data transfer should be minimal. The benefits of SDFS Replication are:
The steps SDFS uses to perform asynchronous replication are the following:
The steps required to setup master/slave replication are the following:
#Number of copies of the replicated folder to keep. This will use First In First Out.
#the password of the master. This defaults to “admin”
#The sdfscli port on the master server. This defaults to 6442
#Replication slave settings#The local ip address that the sdfscli is listening on for the slavevolume.
#The tcp port the sdfscli is listening on for the slave
#The folder where you would like to replicate to wild cards are %d (date as yyMMddHHmmss) %h (remote host)
#Replication service settings#The folder where the SDFS master snapshot will be downloaded to on the slave. The snapshot tar archive is deleted after import.
#The log file that will output replication status
#Schedule cron = as a cron job, single = run one time
#Every 30 minutes take a look at http://www.quartz-scheduler.org/documentation/quartz-2.x/tutorials/tutorial-lesson-06 for scheduling tutorial
#The folder where job history will be persisted. This defaults to a folder call “replhistory” under the same directory where this file is located.
#job.history.folder=/etc/sdfs/replhistory
3. Run the sdfsreplicate script on the slave. This will either run once and exit if schedule.type=single or will run continuously with schedule.type=cron
e.g. sdfsreplicate /etc/sdfs/replication.props
Data Chunk Removal:
SDFS uses two methods to remove unused data from an DedupStorage Engine(DSE). If the SDFS volume has its own dedup storage engine, which it does by default. Unused,or orphaned, chunks are removed as the size of the DSE increases at 10% increments and at specified schedule (defaults to midnight). The specified schedule can me configured at creation with the io-claim-chunks-schedule option. Otherwise it can be configured afterwards within the sdfscli command option –set-gc-schedule. Take a look at cron format for more details. to review the accepted cron syntax. Below details the process for garbage collection.
- SDFS tracks reference counts for all unique data stored in the DSE.
- The DSE checks for data that is no longer referenced.
- The chunks that are no longer referenced are:
- Stand Alone – Compacted from the Data Archive where they are contained
- Cloud Storage – De-referenced from the cloud data archive. Data in the cloud is only removed once all the containing data chunks are removed.
sdfscli --cleanstore
Sizing and Scaling
When running OpenDedupe at scale disk, cpu, and memory requirements need to be considered to size appropriately.
Data Stored on Disk
Cloud Volumes – SDFS Stores file metadata, a local hashtable, and a cache of unique blocks on local disk.
Local Volumes – SDFS Stores file metadata, a local hashtable, and all unique blocks on local disk.
Data Types:
File MetaData – Information about files and folders stored on opendedupe volumes. This data is also stored in the cloud for DR purposes when using cloud storage. File MetaData represents .21% of the non deduplicated size of the file stored.
HashTable – The hashtable is the lookup table that is used to identify whether incoming data is unique. The hashtable is stored on local disk and in the cloud for object storage backed instances. For local instances the hashtable is stored on local disk only. The hashtable is .4% of the unique storage size.
Local Cache – For Object storage backed volumes, active data is cached locally. The local cache stores compressed, deduplicate blocks only. This local cache size is set to 10GB by default but can be set to any capacity required with a minimum of 1GB. The local cache helps with restore performance and accelerated backup performance.
Local Unique Data Store – OpenDedupe stores all unique blocks locally for volumes not backed by object storage. For Object storage backed volumes this is not used. Local storage size will depend on the data being backed up and retention but typically represents 100% of the front end data for a 60 Day retention. OpenDedupe uses a similar variable block deduplication method to a DataDomain so it will be inline with its sizing requirements.
Storage Performance:
Minimum local disk storage performance:
- 2000 random read IOPS
- 2400 random write IOPS
- 180 MB/s of streaming reads
- 120 MB/s of streaming writes
Supported Filesystems:
- VXFS
- XFS
- EXT4
- NTFS (Windows ONLY)
Storage Requirements:
The following percentages should be used to calculate local storage requirements for Object Backed dedupe Volumes:
- MetaData: .21% of Non-Deduped Data Stored
- Local Cache: 10GB by default
- HashTable: .2% of Deduped Data
An example for 100TB of deduped data with an 8:1 dedupe rate would be as follows:
- Logical Data Stored on Disk = 8x100TB = 800TB
- Local Cache = 10GB
- Unique Data Stored in the Object Store 100TB
- MetaData
- .21%Logical Data Stored on Disk=MetaData Size
- .0021x800TB=1.68TB
- HashTable
- .2% * Unique Storage
- .002* 100TB = 400GB
- Total Volume Storage Requirements
- Local Cache + MetaData + Hashtable
- 10GB + 1.68TB + 400GB = 2.09TB
The following percentages should be used to calculate local storage requirements for local dedupe Volumes:
- MetaData: .21% of Non-Deduped Data Stored
- Local Cache: 10GB by default
- HashTable: .2% of Deduped Data
- Unique Data
An example for 100TB of deduped data with an 8:1 dedupe rate would be as follows:
- Logical Data Stored on Disk = 8x100TB = 800TB
- Unique Data Stored on disk 100TB
- MetaData
- .21%Logical Data Stored on Disk=MetaData Size
- .0021x800TB=1.68TB
- HashTable
- .2% * Unique Storage
- .002* 100TB = 400GB
- Total Volume Storage Requirements
- Unique + MetaData + Hashtable +
- 100TB + 1.68TB + 400GB = 102.08TB
Memory Sizing :
Memory for OpenDedupe is primarily used for internal simplified lookup tables (bloom filter) that indicate, with some likelihood that a hash is already stored or not. These data structures take about 256MB per TB of data stored. 3GB of additional base memory is required for other uses.
In addition to memory used by opendedupe you will want to have memory available for filesystem cache to cache the most active parts of the lookup hashtable into ram. For a volume less than 1TB you will need an additional 3GB of ram. For a volume less than 100GB you will need an addition 8GB of RAM. For a volume over 100TB you will need an additional 16GB of ram.
An example for 100TB of deduped data:
- Hash Table Memory
- 200MB per 1TB of Storage
- 200MB x 100TB = 25.6 GB
- 3GB of base memory
- 8GB of Free RAM for Disk Cache
- Total = 25.6+3+8=36.6GB of RAM
CPU Sizing:
As long as the disk meets minimum IO and IOPs requirements the primary limiter for OpenDedupe performance will be CPU at higher dedupe rates. At lower dedupe rates volumes will be limited by the speed of the underlying disk.
For a single 16 Core CPU, SDFS will perform at :
- 2GB/s for 2% Unique Data
- Speed of local disk for 100% unique data. Using minimum requirements this would equal 120MB/s.
TroubleShooting:
There are a few common errors with simple fixes.
1. OutOfMemoryError – This is caused by the size of the DedupStorageEngine memory requirements being larger than the heap size allocated for the JVM. To fix this edit the mount.sdfs script and increase the -Xmx2g to something larger (e.g. -Xmx3g).
2. java.io.IOException : Too Many Open Files – This is caused by there not being enough available file handles for underlying filesystem processes. To fix this add the following lines to /etc/security/limits.conf and the relogin/restart your system.